2024.03.11
*객체직렬화
-직렬화(serialize)란 자바 언어에서 사용되는 Object 또는 Data를 다른 컴퓨터의 자바 시스템에서도 사용 할수 있도록
바이트 스트림(stream of bytes) 형태로 연속전인(serial) 데이터로 변환하는 포맷 변환 기술
-객체가 소멸되어도 객체정보(클래스 정보)와 객체에 들어있던 내용을 사용할 수 있도록 함
*Serializable
-직렬화를 하기 위해서는 반드시 serializable 인터페이스를 구현해주어야 함
public class SerialMain01 {
public static void main(String[] args) {
// 직렬화할 객체 생성
Customer c = new Customer("홍길동");
System.out.println("===객체 직렬화하기===");
FileOutputStream fos = null;
ObjectOutputStream oos = null;
try {
//파일 생성
fos = new FileOutputStream("object.ser");
oos = new ObjectOutputStream(fos);
//객체 직렬화 수행
oos.writeObject(c);
System.out.println("객체 직렬화가 완료되었습니다.");
}
-역직렬화
public class SerialMain02 {
public static void main(String[] args) {
System.out.println("===객체 역직렬화 하기===");
FileInputStream fis = null;
ObjectInputStream ois = null;
try {
//파일 읽기
fis = new FileInputStream("object.ser");
ois = new ObjectInputStream(fis);
//역직렬화 수행
Customer m = (Customer) ois.readObject();
System.out.println(m);
}
*네트워크
-다른 장치로 데이터를 이동시킬 수 있는 컴퓨터들과 주변 장치들의 집합
*포트
-컴퓨터의 주변장치를 접속하기 위한 ‘물리적인 포트’와 프로그램에서 사용되는 접속 장소인 ‘논리적인 포트’가 있음
-포트번호는 인터넷번호 할당 허가 위원회(IANA)에 의해 예약된 포트번호를 가짐
-e.g. 80(HTTP), 21(FTP), 22(SSH), 23(TELNET) 등 (TELNET은 이제 잘 안씀)
*프로토콜
-프로토콜은 클라이언트와 서버간의 통신 규약
-통신 시스템이 데이터를 교환하기 위해 사용하는 통신 규칙
* TCP(Transmission Control Protocol)
-신뢰할 수 있는 프로토콜
-데이터를 상대측까지 제대로 전달되었는지 확인 메시지를 주고 받음으로써 데이터의 송수신 상태를 점검(전화 같음)
-연결형 서비스를 지원하는 프로토콜
*UDP(User Datagram Protocol)
-신뢰할 수 없는 프로토콜
-데이터를 보내기만 하고 확인 메시지를 주고 받지 않기 때문에 제대로 전달했는지 확인하지 않음(편지 같음)
-비연결형 서비스를 지원하는 프로토콜
*java.net.InetAddress
-IP 주소를 표현한 클래스
-InetAddress를 이용해서 IP주소 구하기
package kr.s29.network;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.InetAddress;
import java.net.UnknownHostException;
public class InetAddressMain01 {
public static void main(String[] args) {
BufferedReader br = null;
InetAddress iaddr = null;
String name = null;
try {
br = new BufferedReader(new InputStreamReader(System.in));
System.out.print("도메인명 입력: ");
name = br.readLine();
//InetAddress를 이용해서 IP주소 구하기
iaddr = InetAddress.getByName(name);
System.out.println("호스트 이름: " + iaddr.getHostName());
System.out.println("호스트 IP주소: " + iaddr.getHostAddress()); //여러개면 여러개중 대표 하나를 가져옴
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
}
}
}
}
}
-iaddr = InetAddress.getByName(도메인명): 도메인명으로 IP주소 구하기
-iaddr.getHostName(): 호스트 이름 구하기 (도메인이 있으면 도메인으로 나옴)
-iaddr.getHostAddress(): 호스트 IP주소 구하기(여러개면 대표 하나 구함)
-iaddr = InetAddress.getLocalHost(): 로컬호스트 IP주소 구하기
-addresses = InetAddress.getAllByName(name): 도메인에 매핑되어 있는 모든 주소 읽어오기
*URL
-URL(Uniform Resource Locator)이란 인터넷에서 접근 가능한 자원의 주소를 표현할 수 있는 형식
*java.net.URL
-url.getProtocol(): 프로토콜 가져오기
-url.getHost(): 호스트 이름 가져오기
-url.getDefaultPort(): 기본 포트 가져오기
-url.getPort(): 포트 가져오기. 명시한 포트가 없으면 -1을 반환함
-url.getPath(): 패스 가져오기 (e.g. /index.jsp)
-url.getQuery(): 쿼리 가져오기 (e.g. name=kim)
-url.getRef(): 레퍼런스 가져오기
-콘솔에서 입력받을 때와 네트워크를 통해 서버로부터 입력받을 때 BufferedReader 객체를 따로따로 만들어서 사용함
BufferedReader br = null; //콘솔에서 입력받는 것
BufferedReader input = null; //서버로부터 입력받는 것
try {
//콘솔에서 입력 처리
br = new BufferedReader(new InputStreamReader(System.in));
System.out.print("웹사이트 주소 입력: ");
String name = br.readLine();
URL url = new URL(name);
//네트워크를 통해서 서버로부터 데이터 입력 처리
input = new BufferedReader(new InputStreamReader(url.openStream()));
String line;
while ((line = input.readLine()) != null) {
System.out.println(line);
}
}
[Oracle]
*관계형 데이터베이스
-연산자 이용 가능
-SQL문 사용
*SQL
-SQL은 데이터베이스에서 데이터를 검색, 삽입, 갱신, 삭제할 수 있는 표준 언어
SQL문의 종류
*DDL(Data Definition Language) : 데이터와 그 구조를 정의
| SQL문 | 내용 |
| create | 데이터베이스 객체를 생성 |
| drop | 데이터베이스 객체를 삭제 |
| alter | 기존에 존재하는 데이터베이스 객체를 다시 정의하는 역할 |
*DML(Data Manipulation Language) : 데이터의 검색과 수정 등의 처리
| SQL문 | 내용 |
| insert | 데이터베이스 객체에 데이터를 입력 |
| delete | 데이터베이스 객체에 데이터를 삭제 |
| update | 기존에 존재하는 데이터베이스 객체안의 데이터 수정 |
| select | 데이터베이스 객체로부터 데이터를 검색 |
| merge | 조건에 따라 데이터를 테이블에 삽입 또는 갱신 |
*DCL(Data Control Language) : 데이터베이스 사용자의 권한을 제어
| SQL문 | 내용 |
| grant | 데이터베이스 객체에 권한을 부여 |
| revoke | 이미 부여된 데이터베이스 객체의 권한을 취소 |
*TCL(Transaction Control Language) : 데이터베이스 트랜잭션 제어
| SQL문 | 내용 |
| commit | 보류 중인 모든 변경 내용을 영구히 저장 |
| rollback | 저장점 표시자까지 롤백하는 데 사용 |
| savepoint | 보류 중인 데이터 변경 내용을 모두 버림 |
*SQL문 입력방법
1) SQL 문은 대소문자를 구분하지 않음
2) SQL 문은 한 줄 또는 여러 줄에 입력할 수 있음
3) 키워드는 약어로 표기하거나 여러 줄에 걸쳐 입력할 수 없음
4) 절은 대개 별도의 줄에 입력함
5) 가독성을 높이기 위해 들여쓰기 사용
6) 키워드는 일반적으로 대문자로 입력하지만 테이블 이름, 열 이름 등의 다른 단어는 모두 소문자로 입력
-키워드는 대소문자를 구분하지 않지만 데이터는 대소문자를 구분해서 사용해야함
*dual
-DUAL은 함수 및 계산의 결과를 볼 때 사용할 수 있는 공용(public) 테이블
-사용자 데이터가 있는 테이블에서 유래하지 않은 상수 값, 의사열(pseudo-column), 표현식 등의 값을 단 한번만 돌리거나
현재 날짜, 시각을 알고자 할 때 이용
즉, 일시적인 산술, 날짜 연산등에 주로 이용 (특정 테이블로부터 비롯된 데이터가 아닐 때)
-현재 날짜 읽어오기
SELECT SYSDATE FROM dual;
-아스키코드 불러오는 내장함수
SELECT ASCII('A') FROM dual;
-연산을 통해 메모리에서만 사용가능한 컬럼 생성
SELECT ename, sal, sal+300 AS estimated_sal FROM emp;
*NULL값의 정의
-NULL은 사용할 수 없거나, 할당되지 않았거나, 알 수 없거나, 적용할 수 없는 값
-NULL은 0이나 공백과는 다름
-데이터 입력을 하지 않은 값
(자바에서는 객체가 생성되지 않아 주소가 없다는 뜻)
-NULL 값을 포함하는 산술식은 NULL로 계산됨
*열 ALIAS
-열의 별칭
-열이름 바로 뒤에 나옴. 열 이름과 ALIAS 사이에 선택 사항인 AS 키워드가 올 수도 있음.
SELECT sal*12 Asal FROM emp;
SELECT sal*12 AS Asal From emp;
-대소문자 구별을 원할 때, 공백 포함시, 숫자로 시작할 경우, _#, 등 특수문자 사용시
->알리아스에 큰따옴표를 사용
(_는 큰따옴표 없이 중간에는 올 수 있으나 맨 앞에 오면 오류 발생)
SELECT sal*12 "Annual Salary" From emp;
*연결 연산자
-열이나 문자열을 다른 열에 연결, 두 개의 세로선(||)으로 나타냄
-결과열로 문자식을 생성
SELECT ename || ' has $' || sal FROM emp;(오라클에서는 문자와 문자열의 구별이 없어서 전부 작은 따옴표 사용. 큰따옴표는 알리아스 표기시 사용)
-문자열에 연결 연산자로 NULL값을 결합할 경우 결과는 문자열
(NULL값은 사라짐)
SELECT ename || comm FROM emp;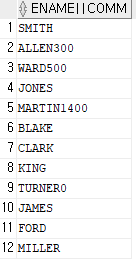
*DISTINCT
-중복행 제거
SELECT DISTINCT deptno FROM emp;
SELECT DISTINCT(deptno) FROM emp;-소괄호: 최우선 연산자(함수 아님)
*WHERE절
-조건 체크 결과 행 제한하기
SELECT * FROM emp WHERE deptno=10;
SELECT ename, job, deptno FROM emp WHERE ename = 'SMITH';
SELECT * FROM emp WHERE hiredate > '81-12-03';
SELECT * FROM emp WHERE hiredate < '81/12/03';- =은 비교연산
-날짜가 특정날짜보다 크다는 것은 그 이후라는 뜻 (작다는 것은 그 이전이라는 뜻)
-날짜를 명시할 때는 / 또는 -를 이용
-(주의) WHERE절에서는 알리아스를 사용할 수 없음
SELECT ename, sal, sal*12 ansal FROM emp WHERE sal*12 > 15000;
*부정 논리 연산자
SELECT * FROM emp WHERE hiredate != '80/12/17';
SELECT * FROM emp WHERE hiredate <> '80/12/17';
SELECT * FROM emp WHERE hiredate ^= '80/12/17';- !=, <>, ^=
*BETWEEN ... AND ...
-두 값 사이(이상 이하)
SELECT * FROM emp WHERE sal BETWEEN 800 AND 3000;
SELECT * FROM mpt WHERE sal >= 800 AND sal <= 3000;
-BETWEEN AND의 부정(NOT BETWEEN)
SELECT * FROM emp WHERE sal NOT BETWEEN 800 AND 3000;
-문자열에도 가능(알파벳 순으로 조건 사이에 해당하는 데이터를 선택)
SELECT * FROM emp WHERE ename BETWEEN 'KING' AND 'SMITH';
*IN
-값 목록 중의 값과 일치
-논리연산자 OR의 개념
SELECT * FROM emp WHERE sal IN (1300, 2450, 3000);
-IN의 부정(NOT IN)
SELECT * FROM emp WHERE sal NOT IN (1300, 2450, 3000);
2024.03.12
*LIKE
-패턴과 일치하는 데이터를 검색
-%는 0개 이상의 문자를 나타냄
-_는 한 문자를 나타냄
S가 처음, 중간, 끝에 오는 이름을 검색
SELECT * FROM emp WHERE ename LIKE '%S%';
입사일이 22로 끝나는 사원 정보 구하기
SELECT ename, hiredate FROM emp WHERE hiredate LIKE '%22';FOR 다음에 꼭 한 글자
SELECT * FROM emp WHERE ename LIKE 'FOR_';
*NULL 조건 사용
SELECT * FROM emp WHERE comm IS NULL;-comm = NULL은 불가능
*ORDER BY
-오름차순 정렬
SELECT * FROM emp ORDER BY sal;
SELECT * FROM emp ORDER BY sal ASC;
-내림차순 정렬
SELECT * FROM emp ORDER BY sal DESC;
-1차 정렬에서 중복값이 있을 경우 2차 정렬 수행
SELECT * FROM emp ORDER BY sal DESC, ename DESC;
-날짜 정렬
SELECT ename, job, deptno, hiredate FROM emp ORDER BY hiredate DESC;시간순서대로 정렬해야 ASC
-열 ALIAS 기준으로 정렬
SELECT empno, ename, sal*12 annsal FROM emp ORDER BY annsal;
-열의 순서값을 지정하여 정렬
SELECT ename, job, deptno, hiredate FROM emp ORDER BY 3;-> 세번째 열을 기준으로 정렬
※열의 순서값은 1부터 시작함
-NULL값을 갖고 있는 컬럼을 기준으로 정렬할 때
NULLS FIRST 또는 NULLS LAST 키워드를 사용 -> NULL값을 포함하는 행이 처음에 오거나 마지막에 오도록 지정 가능
SELECT * FROM emp ORDER BY comm NULLS FIRST;
SELECT * FROM emp ORDER BY comm NULLS LAST;SELECT * FROM emp ORDER BY comm NULLS LAST, ename DESC;
*대소문자 조작함수: LOWER, UPPER, INITCAP
SELECT LOWER(ename) FROM emp;
SELECT INITCAP('hello wORLD') FROM dual;
*문자 조작함수
-CONCAT(문자열1, 문자열2) : 문자열1과 문자열2를 연결하여 하나의 문자열로 반환
SELECT CONCAT(ename, job) FROM emp;
-SUBSTR(대상문자열, 인덱스): 대상문자열에서 지정한 인덱스부터 문자열을 추출
SUBSTR(대상문자열, 인덱스, 문자의 개수)
※인덱스 1부터 시작(웬만한 데이터베이스는 모두 인덱스가 1부터 시작)
SELECT SUBSTR('Hello World', 3) FROM dual; --llo World
SELECT SUBSTR('Hello World', 3, 3) FROM dual; --llo 인덱스 3부터 문자 3개 추출
SELECT SUBSTR('Hello World', -3) FROM dual; --rld 뒤에서 3번째부터 끝까지 추출
SELECT SUBSTR('Hello World', -3, 2) FROM dual; --rl 뒤에서 3번째부터 문자 2개 추출
-LENGTH(대상문자열): 문자열의 길이
SELECT LENGTH('Hello World') FROM dual;
SELECT ename, LENGTH(ename) FROM emp;
-INSTR(대상문자열, 검색문자): 검색문자의 위치값검색
SELECT INSTR('Hello World', 'e') FROM dual;검색문자가 없을 경우 0 반환
검색문자가 여러개일 경우 앞에 있는 값의 인덱스 반환
INSTR(대상문자열, 검색문자, 검색 인덱스[해당 위치부터 검색])
SELECT INSTR('Hello World', 'o') FROM dual; --5
SELECT INSTR('Hello World', 'o', 6) FROM dual; --8
INSTR(대상문자열, 검색문자, 검색인덱스, 반복횟수)
반복횟수: 문자열의 검색인덱스부터 반복횟수로 지정한 횟수만큼 검색해서 결과 인덱스를 반환
(대상문자열 전체를 여러번 검색한다는 의미X)
SELECT INSTR('Hello World', 'o', 1, 2) FROM dual; --8
-LPAD, RPAD(대상문자열, 총길이, 문자) : 지정한 길이로 문자열을 출력하는데 각각 왼쪽/오른쪽 공백은 지정한 문자로 채움
SELECT LPAD('Hello',10,'*') FROM dual; --*****Hello결과를 출력할 때 공백이 필요한 경우 유용
-TRIM: 문자열에서 공백이나 특정 문자를 제거한 다음 값을 반환
방향: 왼쪽 -> LEADING, 오른쪽 -> TRAILING, 양쪽 -> BOTH (default)
SELECT TRIM(LEADING 'h' FROM 'habchh') FROM dual; --abchh
-LTRIM, RTRIM: 문자열의 왼쪽/오른쪽에서 공백이나 특정 문자를 제거한 다음 값을 반환
-REPLACE(대상문자열, OLD, NEW): 대상문자열에서 OLD문자를 NEW문자로 대체
SELECT REPLACE('010.1234.5678', '.', '-') FROM dual;
*함수 중첩
SELECT ename, LOWER(SUBSTR(ename, 1, 3)) FROM emp;
[실습]
4.이름이 J,A 또는 M으로 시작하는 모든 사원의 이름(첫 글자는 대문자로, 나머지 글자는 소문자로 표시) 및
이름의 길이를 표시하시오. (열 레이블은 name, length)
SELECT INITCAP(ename) name, LENGTH(ename) length FROM emp
WHERE ename LIKE 'J%' OR ename LIKE 'A%' OR ename LIKE 'M%';
SELECT INITCAP(ename) name, LENGTH(ename) length FROM emp
WHERE SUBSTR(ename, 1,1) IN ('J', 'A', 'M')
*숫자함수
-CEIL(실수): 올림 처리한 정수값을 반환
-FLOOR(실수): 버림 처리한 정수값을 반환
-ROUND(대상숫자, 지정자릿수): 반올림
SELECT ROUND(45.926, 2) FROM dual; --45.39
SELECT ROUND(45.926) FROM dual; --46
SELECT ROUND(45.926, -1) FROM dual; --50
-TRUNC(대상숫자, 지정자릿수): 절삭
SELECT TRUNC(45.926, 2) FROM dual; --45.92
SELECT TRUNC(45.926) FROM dual; --45
-MOD(대상숫자, 나눌 숫자): 나머지값
SELECT MOD(17,2) FROM dual; --1
*날짜함수
-날짜에 산술 연산자 사용
SELECT ename, (SYSDATE - hiredate)/7 AS weeks FROM emp WHERE deptno = 10;
-MONTHS_BETWEEN(날짜1, 날짜2): 두 날짜 간의 월 차이
SELECT MONTHS_BETWEEN('2012-03-23', '2010-01-23') FROM dual;-큰 날짜가 먼저 오도록
-ADD_MONTHS: 특정 날짜의 월에 정수를 더한 다음 해당 날짜를 반환하는 함수
SELECT ADD_Months('2022, 01, 01', 8) FROM dual;
-NEXT_DAY: 지정된 요일의 다음 날짜
1(일요일) ~ 7(토요일)
SELECT NEXT_DAY('2024.03.12','월요일') FROM dual;
SELECT NEXT_DAY('2024-03-12', 2) FROM dual;
-LAST_DAY: 월의 마지막 날
SELECT LAST_DAY('2012-12-07') FROM dual;
-EXTRACT: 날짜 정보에서 특정한 연도, 월, 일, 시간, 분, 초 등을 추출
SELECT EXTRACT(YEAR FROM SYSDATE),
EXTRACT(MONTH FROM SYSDATE),
EXTRACT(DAY FROM SYSDATE) FROM dual;
*명시적 데이터 유형 변환
-TO_NUMBER : 문자 -> 숫자
-TO_CHAR : 숫자 -> 문자, 날짜 -> 문자
-TO_DATE : 문자 -> 날짜
*날짜 포맷팅
: TO_DATE()와 TO_CHAR(날짜) 함수에서 사용할 수 있는 포맷팅 옵션
| AD, A.D. - AD 표시 |
| AM, PM, A.M.,P.M. - 오전/오후 표시 |
| BC, B.C. -> BC 표시 |
| RM - 월의 로마식 표기 |
| CC, SCC - 세기 표시(1999는 20세기로, 2001은 21세기로 표현됨) |
| Y,YY,YYY,YYYY - 연도의 숫자값(각각 1,2,3,4 자리로 표현) |
| YEAR - 연도를 문자로 표현(예, “Two thousand one”) |
| RR - 네 자리 연도 숫자 중 뒤의 두 자리를 사용하여 앞의 두 자리 수자를 반환. 뒤의 두 자리가 50보다 작을 때는 현재 세기가 그대로 사용되지만, 50이상이면 1을 줄여 사용한다는 것에 주의 (예) RR(‘99’) = 1999, RR(‘00’) = 2000 |
| MON - 월의 세 자리 문자식 표현(JAN,FEB 등) |
| MONTH - 월의 문자식 표현(JANUARY, FEBRUARY 등) |
| MM - 월의 숫자식 표현(1~12) |
| WW - 주간의 숫자식 표현(1~53) |
| W - 월 내의 주간을 숫자식으로 표현(1~5) |
| D - 주간 내의 일을 숫자식으로 표현(1~7) |
| DD - 월 내의 일을 숫자식으로 표현(1~31) |
| DDD - 연도 내의 일을 숫자식으로 표현(1 ~ 365) |
| Day - 주간 내의 일을 문자식으로 표현 |
| HH, HH12 - 시간(1~12) |
| HH24 - 24시간식 표현(0~23) |
| MI - 분(0~59) |
| SS - 초(0~59) |
| SSSS - 자정 이후 하루 내의 초 단위(0~86399) |
| Q - 분기(1,2,3,4) 1은 1월에서 3월까지 |
*TO_CHAR: 숫자 -> 문자, 날짜 -> 문자
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') FROM dual;
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH:MI:SS') FROM dual; --12시 표기법
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') FROM dual; --24시 표기법한글 입력 불가
*숫자 포맷팅
-ROUND()와의 차이점: 결과값이 문자열로 반환됨
| 9 - 숫자를 주어진 자리수대로 반환(예, TO_CHAR(111,999) = 111) |
| 0 - 0 이 표시되도록 강제 적용 |
| 9,999 - 정해진 위치에 콤마를 넣는다.(예, TO_CHAR(1234,’9,999’) = 1,234) |
| 999.00 - 정해진 위치에 소수점을 넣는다.(예, TO_CHAR(123,’999.99’) = 123.00) |
| $9999 - 숫자 앞에 달러 기호를 넣는다. |
-실제 자릿수와 일치
SELECT TO_CHAR(1234, 9999) FROM dual; --숫자형태
SELECT TO_CHAR(1234, '9999') FROM dual; --문자형태
SELECT TO_CHAR(1234, '0000') FROM dual;
-자릿수가 모자람 -> ####
SELECT TO_CHAR(1234, 999) FROM dual; --####
-실제 자릿수보다 많은 자릿수 지정
SELECT TO_CHAR(1234, 99999) FROM dual; --' 1234' (앞에 모자란 자리만큼 공백)
SELECT TO_CHAR(1234, '99999') FROM dual; --' 1234' (앞에 모자란 자리만큼 공백)
SELECT TO_CHAR(1234, '00000') FROM dual; --'01234' (앞에 모자란 자리만큼 0)
-소수점 자리 지정
SELECT TO_CHAR(1234, 9999.99) FROM dual; --1234.00
SELECT TO_CHAR(1234, '9999.99') FROM dual; --1234.00
SELECT TO_CHAR(1234, '0000.00') FROM dual; --1234.00
-인상된 급여를 소수점 첫째자리까지 표시
SELECT TO_CHAR(sal*1.15, '9,999.9') FROM emp;
-통화 표시
SELECT TO_CHAR(1234, '$0000') FROM dual;
-지역 통화 표시(프로그램이 설치된 지역 반영)
SELECT TO_CHAR(1234, 'L0000') FROM dual;
*TO_DATE: 문자 -> 날짜
-구분자는 '-' 또는 '/' 이어야 함
-자동 형변환이 안되는 경우에는 TO_DATE를 사용하여 명시적으로 날짜로 형변환
SELECT TO_DATE('24-03-12', 'YYYY-MM-DD') FROM dual;
-포맷형식 생략 가능
SELECT TO_DATE('24-03-12') FROM dual;
*TO_NUMBER: 문자 -> 숫자
SELECT TO_NUMBER('100', 999) FROM dual;
-포맷형식 생략 가능
SELECT TO_NUMBER('100') FROM dual;
2024.03.13
*일반함수 - NULL 관련
-NVL(value1, value2): value1이 NULL이면 value2를 사용
value1과 value2의 자료형이 일치해야 함
NULL값을 포함한 열을 이용해서 연산을 하고 싶을 때 유용(연산에 NULL이 포함되면 결과가 NULL이 됨)
SELECT ename, sal, comm, (sal + comm)*12 FROM emp;
SELECT ename, sal, NVL(comm, 0), (sal + NVL(comm, 0))*12 FROM emp;
-value1과 value2의 자료형이 같아야 하므로 숫자-> 문자로 자료형 맞춰주기
SELECT ename, NVL(TO_CHAR(comm),'No Comission') FROM emp;
-NVL2(value1, value2, value3): value1이 null인지 평가. null이면 value3, null이 아니면 value2 사용.
자료형이 일치하지 않아도 됨.
SELECT NVL2(comm, 'commission', 'no commission') FROM emp;
-NULLIF(value1, value2): 두 개의 값이 일치하면 NULL, 두 개의 값이 일치하지 않으면 value1 사용.
SELECT NULLIF(LENGTH(ename), LENGTH(job)) "NULLIF" FROM emp;
-COALESCE(value1, value2, value3...): NULL이 아닌 값을 사용
자료형 일치해야 함
SELECT comm, sal, COALESCE(comm, sal, 0)FROM emp;
SELECT comm, mgr, sal, COALESCE(comm, mgr, sal) FROM emp;
*조건 체크
-CASE - WHEN - THEN - ELSE - END
CASE 컬럼 WHEN 비교값 THEN 결과값
WHEN THEN
(ELSE 결과값)
END
--이퀄 비교
SELECT ename, sal, job,
CASE job WHEN 'SALESMAN' THEN sal*0.1
WHEN 'MANAGER' THEN sal*0.2
WHEN 'ANALYST' THEN sal*0.3
ELSE sal*0.4
END "Bonus"
FROM emp;
--범위 비교
SELECT ename, sal, job,
CASE WHEN sal>=4000 AND sal<=5000 THEN 'A'
WHEN sal>=3000 AND sal<4000 THEN 'B'
WHEN sal>=2000 AND sal<3000 THEN 'C'
WHEN sal>=1000 AND sal<2000 THEN 'D'
ELSE 'F'
END "Grade"
FROM emp;
-여러 행을 읽어서 작업을 하기 위해서는 자바에서 처리할 작업이 많아져 시간이 이중으로 걸리기 때문에
SQL에서 연산해서 가져오는 것이 좋음.
-DECODE
-이퀄 비교만 가능, 오라클 전용
-Java의 스위치와 유사
DECODE(컬럼, 비교값, 반환값,
비교값, 반환값,
반환값)
-미리 연산을 해서 DECODE()를 사용하면 더 간결함
SELECT ename, sal, job,
DECODE(TRUNC(sal/1000), 5, 'A',
4, 'A',
3, 'B',
2, 'C',
1, 'D',
'F') "Grade"
FROM emp;
*그룹함수
-행 집합 연산을 수행하여 그룹별로 하나의 결과를 산출
-AVG(): NULL을 제외한 모든 값들의 평균을 반환, NULL값은 평균 계산에서 무시됨
SELECT ROUND(AVG(sal)) FROM emp;
-COUNT(): NULL을 제외한 값을 가진 모든 레코드의 수를 반환.
COUNT(*)의 형식을 사용하면 NULL도 계산에 포함
SELECT COUNT(empno) FROM emp;
SELECT COUNT(comm) FROM emp;
SELECT COUNT(*) FROM emp;
-MAX(): 레코드 내에 있는 여러 값 중 가장 큰 값을 반환
SELECT MAX(sal) FROM emp;
SELECT MAX(ename) FROM emp;
-MIN(): 레코드 내에 있는 여러 값 중 가장 작은 값을 반환
SELECT MIN(sal) FROM emp;
-SUM(): 레코드들이 포함하고 있는 모든 값을 더하여 반환
SELECT SUM(sal) FROM emp;
-WHERE 절로 그룹을 지정하여 그룹 내에서만 연산할 수 있음
SELECT MAX(sal), MIN(sal), ROUND(AVG(sal)), SUM(sal) FROM emp WHERE deptno=10;
-GROUP BY: SELECT절에 집합함수 적용시 개별 컬럼을 지정할 수 없음.
개별 컬럼을 지정할 경우에는 반드시 GROUP BY 절에 지정된 컬럼만 가능.
SELECT deptno, MAX(sal) FROM emp GROUP BY deptno;
-그룹별로 사원수 구하기
SELECT deptno, COUNT(empno) FROM emp GROUP BY deptno ORDER BY deptno;
-그룹 안에 또 그룹 만들기
SELECT deptno, job, SUM(sal) FROM emp GROUP BY deptno, job ORDER BY deptno;
-HAVING: 그룹 함수를 이용해서 조건 체크를 해야 할 경우
알리아스 사용 불가
[오류 발생]
SELECT deptno, AVG(sal) FROM emp WHERE AVG(sal) >= 2000 GROUP BY deptno;
--WHERE절에 그룹함수를 이용해서 조건을 체크하면 오류 발생
[정상 구문]
SELECT deptno, AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) >= 2000;
-그룹 함수 중첩
SELECT MAX(AVG(sal)) FROM emp GROUP BY deptno;
-분기별로 입사한 사원의 수
SELECT TO_CHAR(hiredate, 'Q') quarter, COUNT(empno) FROM emp
GROUP BY TO_CHAR(hiredate, 'Q')
ORDER BY quarter;c.f. 날짜에서 분기 구하기: TO_CHAR(date, 'Q')
-HAVING에는 꼭 그룹함수 뿐 아니라 일반 컬럼을 넣어도 문제 없음
SELECT deptno, COUNT(*) FROM emp WHERE deptno=30 GROUP BY deptno;
SELECT deptno, COUNT(*) FROM emp GROUP BY deptno HAVING deptno=30 ;
*분석 함수
-RANK(): 순위를 표현할 때 사용하는 함수
RANK(순위를 구하려는 데이터) WITHIN GROUP (ORDER BY 인자의 컬럼명): 특정 데이터의 순위 확인하기
※주의: RANK 뒤에 나오는 데이터와 ORDER BY 뒤에 나오는 데이터는 같은 컬럼이어야 함
SELECT RANK('SMITH') WITHIN GROUP (ORDER BY ename) "RANK" FROM emp;
SELECT RANK('SMITH') WITHIN GROUP (ORDER BY ename DESC) "RANK" FROM emp;
-RANK() OVER(ORDER BY 컬럼명): 전체순위 보기
SELECT empno, ename, sal, RANK() OVER(ORDER BY sal) FROM emp;
-PARTITION BY: 그룹별로 그룹 내 순위 구하기
SELECT empno, ename, sal, deptno,
RANK() OVER(PARTITION BY deptno ORDER BY sal DESC) "RANK" FROM emp;
--2차그룹
SELECT empno, ename, sal, deptno, job,
RANK() OVER(PARTITION BY deptno, job ORDER BY sal DESC) "RANK" FROM emp;
*JOIN
-둘 이상의 테이블을 연결하여 데이터를 검색하는 방법
-보통 둘 이상의 행들의 공통된 값 PRIMARY KEY 및 FPREIGN KEY 값을 사용하여 조인
-두 개의 테이블을 SELECT 문장 안에서 조인하려면 적어도 하나의 컬럼이 그 두 테이블 사이에서 공유되어야 함
*Cartesian Product(카티션 곱)
-검색하고자 했던 데이터뿐 아니라 조인에 사용된 테이블들의 모든 데이터가 반환되는 현상
-조인 조건을 잘못 준 것
-에러가 나거나 잘못된 정보가 출력됨
*Cartesian product는 다음과 같은 경우 발생
-조인 조건을 정의하지 않았을 경우
-조인 조건이 잘못된 경우
-첫 번째 테이블의 모든 행들이 두 번째 테이블의 모든 행과 조인이 되는 경우
Oracle 전용 조인 구문
*동등 조인(Equi JOIN)
-조건절에 =(이퀄) 조건에 의하여 조언이 이루어짐
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
SELECT emp.ename, dept.dname FROM emp, dept WHERE emp.deptno = dept.deptno;
-테이블에 알리아스 부여하기
SELECT e.ename, d.dname FROM emp e, dept d WHERE e.deptno = d.deptno;
-컬럼명을 호출할 때 테이블명 또는 테이블 알리아스 생략하기
한 테이블에만 있는 컬럼명은 테이블명을 생략할 수 있음
SELECT ename, dname, d.deptno FROM emp e, dept d WHERE e.deptno = d.deptno;
-추가적인 조건 명시하기
AND 연산자를 사용해 명시
WHERE 조인조건 AND 추가적인 조건
SELECT e.ename, d.dname FROM emp e, dept d WHERE e.deptno=d.deptno AND e.ename='ALLEN';
SELECT ename, sal, dname dept FROM emp e, dept d WHERE e.deptno = d.deptno AND sal BETWEEN 3000 AND 4000;
*비동등 조인(Non Equi Join)
-테이블의 어떤 column도 join할 테이블의 column에 일치하지 않을 때 사용
-조인 조건은 동등(=)이외의 연산자를 갖음.(between and, is null, is not null, in, not in)
-데이터의 종류는 같아야 함
-미리 비동등 조인을 염두에 두고 만든 테이블이 아니면 발생하기 힘듦
-사원이름, 급여, 급여등급 구하기(emp, salgrade 테이블 이용)
SELECT e.ename, e.sal, s.grade FROM emp e, salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal;
*SELF JOIN
-동일한 테이블 조인
-미리 SELF JOIN을 염두에 두고 만든 테이블이 아니면 발생하기 힘듦
SELECT e.ename 사원이름, m.ename 관리자이름 FROM emp e, emp m WHERE e.mgr = m.empno;
-조인할 컬럼이 NULL값인 행은 출력되지 않음
*외부 조인(Outer Join)
-Equi Join 문장들의 한가지 제약점은 조인을 생성하려 하는 두 개의 테이블의 두 개 컬럼에서 공통된 값이 없다면
테이블로부터 데이터를 반환하지 않는다는 것. (NULL 값 포함)
-정상적으로 조인 조건을 만족하지 못하는 행들을 보기 위해 Outer Join을 사용.
-> 누락된 행을 보여줌
-누락되지 않은 테이블의 조인조건에 (+)를 붙여 표기
SELECT DISTINCT(e.deptno), d.deptno FROM emp e, dept d WHERE e.deptno(+)=d.deptno;
SELECT e.ename 사원이름, m.ename 관리자이름 FROM emp e, emp m WHERE e.mgr=m.empno(+);
2024.03.14
-COUNT() 할 때 COUNT(*)을 넣으면 NULL값까지 카운팅 한다는 점 주의
SELECT d.loc, COUNT(e.empno) members FROM emp e, dept d
WHERE e.deptno(+)=d.deptno GROUP BY d.loc HAVING COUNT(d.loc) < 5 ORDER BY members;
표준 SQL 조인
*내부 조인(Inner Join)
SELECT emp.ename, dept.deptno FROM emp INNER JOIN dept ON emp.deptno=dept.deptno;
SELECT emp.ename, dept.deptno FROM emp JOIN dept ON emp.deptno=dept.deptno;-INNER JOIN/JOIN - ON 사용
-ON절은 JOIN 조건을 명시하고 WHERE에 부가 조건을 명시
-만약 JOIN 조건에 사용된 컬럼의 이름이 같다면 USING절을 사용하여 조인 조건을 정의할 수 있음
-양쪽 테이블에 있는 컬럼을 합쳐서 표시하는 방식
※USING(컬럼명) 절에 명시한 컬럼명을 호출할 때는 테이블명 또는 알리아스를 명시해서 호출 불가
SELECT * FROM emp e JOIN dept d USING(deptno);
SELECT e.ename, d.deptno FROM emp e JOIN dept d USING(deptno); --에러
SELECT e.ename, deptno, d.dname FROM emp e JOIN dept d USING(deptno); --정상 동작
-USING 절에서는 테이블명(알리아스)를 생략 가능
SELECT ename, deptno, dname FROM emp JOIN dept USING(deptno);
-셀프조인
셀프조인은 조인하는 컬럼명이 다르기 때문에 ON절을 사용해야 함
SELECT e.ename name, m.ename manager_name FROM emp e JOIN emp m ON e.mgr=m.empno;
*외부 조인(Outer Join)
-누락된 행의 방향 표시
SELECT DISTINCT(e.deptno), d.deptno FROM emp e RIGHT OUTER JOIN dept d ON e.deptno=d.deptno;
-사원이름과 해당 사원의 관리자 이름 구하기(관리자 없는 사원도 표시)
SELECT e.ename name, m.ename manager_name FROM emp e LEFT OUTER JOIN emp m ON e.mgr=m.empno;사원 이름이 누락된 거니까 LEFT OUTER JOIN 해줌
*다중 조인
-오라클 전용 방법: 열거 방식으로 표현
SELECT e.ename, d.deptno, d.dname, e.sal, s.grade
FROM dept d, emp e, salgrade s WHERE d.deptno=e.deptno AND e.sal BETWEEN s.losal AND s.hisal
AND e.deptno=10;
-표준 SQL 방법: 두개의 테이블씩 JOIN과 ON절 표현
SELECT e.ename, d.deptno, d.dname, e.sal, s.grade
FROM dept d JOIN emp e ON d.deptno=e.deptno
JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal
WHERE e.deptno=10;
집합연산자
*UNION
-합집합 중복값 제거
-두 테이블의 결합을 나타내며 결합시키는 두 테이블의 중복되지 않은 값들을 반환
SELECT deptno FROM emp
UNION
SELECT deptno FROM dept;
*UNION ALL
-UNION과 같으나 두 테이블의 중복되는 값까지 반환
SELECT deptno FROM emp
UNION ALL
SELECT deptno FROM dept;
*INTERSECT
-두 행의 집합 중 공통된 행을 반환
SELECT deptno FROM emp
INTERSECT
SELECT deptno FROM dept;
*MINUS
-첫번째 SELECT문에 의해 반환되는 행 중에서 두번째 SELECT문에 의해 반환되는 행의 존재하지 않는 행들을 보여줌
SELECT deptno FROM dept
MINUS
SELECT deptno FROM emp;
*서브쿼리(SUBQUERY)
-다른 하나의 SQL문장의 절에 NESTED된 SELECT문장
*단일행 서브쿼리
-오직 한 개의 행(값)을 반환
-프라이머리키 제약조건: 조건이 되는 컬럼이 프라이머리키여야 함 (그래야 단일행이 유지됨)
SELECT job FROM emp WHERE empno=7369;
SELECT empno, ename, job FROM emp WHERE job='CLERK'
-> 위의 두개의 문장을 서브쿼리를 사용해서 작성
SELECT empno, ename, job FROM emp WHERE job = (SELECT job FROM emp WHERE empno=7369);-() 부분은 소괄호 내 서브쿼리의 결과를 반환함
-여기서 empno는 unique한 값 => 하나의 레코드만 검색됨
-이름과 같은 키는 중복될 수 있기 때문에 단일행이 아님
*다중행 서브쿼리
-프라이머리키를 사용하거나 그룹함수를 사용하는 경우가 아니라면 모두 다중행 서브쿼리로 봐야함
`IN 연산자의 사용
-이퀄 관계
-부서별로 가장 급여를 적게 받는 사원과 동일한 급여를 받는 사원의 정보를 출력하시오
SELECT * FROM emp WHERE sal IN (SELECT MIN(sal) FROM emp GROUP BY deptno);
`ANY 연산자의 사용
-크거나 같거나 등등의 관계
-ANY 연산자는 서브쿼리의 결과값 중 어느 하나의 값이라도 만족이 되면 결과값을 반환
-OR의 개념
SELECT sal FROM emp WHERE job = 'SALESMAN';
SELECT ename, sal FROM emp WHERE sal>1250 OR sal>1500 OR sal>1600;
-> 위 문장을 서브쿼리로 작성
SELECT ename, sal FROM emp WHERE sal > ANY (SELECT sal FROM emp WHERE job = 'SALESMAN');
`ALL 연산자의 사용
-크거나 같거나 등등의 관계
-서브쿼리의 결과와 모든 값이 일치
-AND의 개념
SELECT sal FROM emp WHERE deptno=20;
SELECT empno, ename, sal, deptno FROM emp WHERE sal>800 AND sal>2975 AND sal>3000;
->위 문장을 서브쿼리로 작성
SELECT empno, ename, sal, deptno FROM emp WHERE sal > ALL(SELECT sal FROM emp WHERE deptno=20);
*다중열 서브쿼리
-서브 쿼리의 결과가 두 개 이상의 컬럼으로 반환되어 메인 쿼리에 전달하는 쿼리
-데이터 면에서 의미있는 출력은 아니지만, 여러 개의 열을 비교하는 방법으로 실무에서 유용하게 쓰임
SELECT empno, ename, sal, deptno FROM emp
WHERE (deptno, sal) IN (SELECT deptno, sal FROM emp WHERE deptno=30);
-부서별로 가장 급여를 적게 받는 사원의 정보를 출력
SELECT empno, ename, sal, deptno FROM emp
WHERE (deptno, sal) IN (SELECT deptno, MIN(sal) FROM emp GROUP BY deptno);
-부서별로 가장 급여를 적게 받는 사원과 동일한 급여를 받는 사원 정보를 출력
SELECT empno, ename, sal, deptno FROM emp
WHERE sal IN (SELECT MIN(sal) FROM emp GROUP BY deptno);
*인라인뷰
-메인 쿼리의 FROM절을 서브 쿼리로 이용하는 방법
-서브쿼리를 이용해서 읽어온 것을 가상의 테이블처럼 이용
SELECT empno, ename, deptno FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=20);
-인라인뷰를 테이블처럼 이용하여 조인
SELECT e.empno, e.ename, d.dname FROM (
SELECT empno, ename, deptno FROM emp
WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=20)) e JOIN dept d ON e.deptno=d.deptno;
-일반적인 JOIN으로도 작업 가능
SELECT e.empno, e.ename, d.dname FROM emp e JOIN dept d ON e.deptno=d.deptno
WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=20);
*스칼라 서브쿼리
-스칼라값은 단일 값을 의미함
-결과값이 단일 행, 단일 열의 스칼라값으로 반환됨
SELECT deptno, (SELECT dname FROM dept WHERE deptno=e.deptno), SUM(sal) FROM emp e GROUP BY deptno;-컬럼명의 위치에서 값을 하나씩 보내서 반환값을 하나씩 받아옴(조인 없이 루프를 돌면서 단일값을 만들어냄)
[실습문제]
1."BLAKE"와 같은 부서에 있는 사원들의 이름과 입사일을 구하는데 "BLAKE"는 제외하고 출력하시오.
SELECT ename, hiredate, deptno FROM emp
WHERE deptno IN (SELECT deptno FROM emp WHERE ename = 'BLAKE') AND ename != 'BLAKE';-이름은 프라이머리키가 아니기 때문에 다중행으로 생각하고 구해야함!!
4.(부서별 사원수를 구하고) 사원수가 3명 이하의 부서의 부서명과 사원수를 출력하시오.
[MY ANSWER]
SELECT d.dname, COUNT(e.empno) members
FROM dept d LEFT OUTER JOIN emp e ON d.deptno=e.deptno
GROUP BY d.dname
HAVING COUNT(e.empno) <= 3;
[인라인뷰]
SELECT a.dname, b.cnt
FROM dept a, (SELECT deptno, COUNT(empno) cnt FROM emp GROUP BY deptno) b
WHERE a.deptno=b.deptno AND b.cnt <= 3;
[조인]
SELECT d.dname, COUNT(e.empno) cnt
FROM emp e, dept d WHERE e.deptno=d.deptno
GROUP BY d.dname
HAVING COUNT(e.empno) <= 3;
6.직속상사(mgr)가 KING인 모든 사원의 이름과 급여를 출력하시오.
[MY ANSWER]
SELECT e.ename, e.sal FROM emp e, emp m WHERE e.mgr=m.empno AND m.ename='KING';
[IN CLASS]
SELECT ename, sal FROM emp WHERE mgr IN(SELECT empno FROM emp WHERE ename='KING');
2024.03.15
*INSERT문: 테이블에 행을 삽입
-전체 데이터 삽입(전체 컬럼 명시시)
INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
VALUES (8000, 'DENNIS', 'SALESMAN', 7698, '99/01/22',1700, 200, 30);
-전체 데이터 삽입할 때는 컬럼명 생략 가능
INSERT INTO emp
VALUES (8001, 'SUNNY', 'SALESMAN', 7698, '99/03/01', 1000, 300, 30);
*NULL 삽입 방법
-값이 입력되지 않는 컬럼은 제외
INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, deptno)
VALUES (8003, 'PETER', 'CLERK', 7698, '22/11/06', 1700, 20);
-값이 입력되지 않는 컬럼을 제외하지 않았을 경우
INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
VALUES (8004, 'ANNIE', 'CLERK', 7698, '22/11/06', 1800, NULL, 30);
*날짜의 삽입
INSERT INTO emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
VALUES (8005, 'MICHAEL', 'CLERK', 7698, TO_date('22/11/06', 'YY/MM/DD'), 1800, NULL, 30);-날짜 형식으로만 문자열을 적으면 포맷팅 없이도 자동 변환됨
*UPDATE문: 행 단위로 데이터 갱신
UPDATE emp SET mgr=7900 WHERE empno=8000;
UPDATE emp SET ename='MARIA', sal=2500, comm=500 WHERE empno=8000;
-WHERE절을 명시하지 않으면 전체 행의 데이터를 수정
UPDATE emp SET ename='KINGKONG';);
*ROLLBACK
-커밋하기 전에 방금 전에 했던 작업 취소하기
*DELETE문: 행을 삭제
DELETE FROM emp WHERE empno=7369;
-WHERE절을 명시하지 않으면 모든 행이 삭제
DELETE FROM emp;
*데이터베이스 트랜잭션
-트랜잭션은 데이터 처리의 한 단위
-오라클 서버에서 발생하는 SQL문들은 하나의 논리적인 작업 단위이며, 성공하거나 실패하는 일련의 SQL문을 트랜잭션이라고 할 수 있음
-트랜잭션은 데이터를 일관되게 변경하는 DML 문장으로 구성됨
-DDL문장이나 DCL문장을 실행하면 트랜잭션이 중단되기 때문에 주의
*COMMIT(변경사항 저장) & ROLLBACK(변경사항 취소)
-데이터의 일관성을 제공
-데이터를 영구적으로 변경하기 전에 데이터 변경을 확인하게 함
-관련된 작업을 논리적으로 그룹화 함
-COMMIT, ROLLBACK 문장으로 트랜잭션의 논리를 제어
*COMMIT/ROLLBACK 이전의 상태
-현재 사용자는 SELECT문장으로 DML작업의 결과를 확인
-다른 사용자는 SELECT문장으로 현재 사용자가 사용한 DML문장의 결과를 확인할 수 없음
-변경된 행은 LOCK이 설정되어서 다른 사용자가 변경할 수 없음
*데이터베이스 객체
-오라클에 저장된 후 서비스되는 것
| 객체 | 설명 |
| 테이블 | 기본 저장 단위로 행과 열로 구성 |
| 뷰 | 논리적으로 하나 이상의 테이블에 있는 데이터의 부분 집합을 나타냄 |
| 시퀀스 | 숫자 값 생성기 |
| 인덱스 | 질의의 성능을 향상 |
| 동의어 | 객체에 다른 이름을 제공 |
*테이블
-기본적인 데이터 저장 단위
-레코드(행)와 컬럼(열)으로 구성
-레코드(record/row): 테이블의 데이터는 행에 저장
-컬럼(column): 테이블의 각 컬럼은 데이터를 구별할 수 있는 속성을 표현
*테이블 이름 지정 규칙
-문자로 시작해야 함
-1~30자까지 가능
-A~Z,a~z,0~9,_,$,#만 포함해야 함
-동일한 사용자(계정)가 소유한 다른 객체의 이름과 중복되지 않아야 함
-오라클 서버의 예약어가 아니어야 함
*데이터 딕셔너리 질의
-사용자가 소유한 테이블의 이름
SELECT table_name FROM user_tables;
-사용자가 소유한 개별 객체 유형
SELECT DISTINCT(object_type) FROM user_objects;
-사용자가 소유한 테이블, 뷰, 동의어 및 시퀀스
SELECT * FROM user_catalog;
*테이블 생성 시 제약조건
| 제약조건 | 설명 |
| primary key(PK) | 유일하게 테이블의 각 행을 식별(not null과 unique 조건을 만족) |
| foreign key(FK) | 열과 참조된 열 사이의 외래키 관계를 적용하고 설정 (다른 테이블의 기본키를 참조할 때) |
| unique key(UK) | 테이블의 모든 행을 유일하게 하는 값(null 허용) |
| not null(NN) | 열은 null값을 포함할 수 없음 |
| check(ck) | 해당 컬럼에 저장 가능한 데이터 값의 범위나 사용자 조건을 지정 |
*오라클 데이터 타입
| Data Type | 설명 |
| varchar2(n) | 가변 길이 문자 데이터(1~4000byte) |
| char(n) | 고정 길이 문자 데이터(1~2000byte) |
| number(p,s) | 십진 자릿수 p고 소수점 이하 자릿수가 s인 숫자. 십진 자릿수의 범위는 1부터 38까지고 소수점 이하 자리수의 범위는 -84부터 127까지 |
| date | 날짜와 시간(초까지 표시) 기원전 4712년 1월 1일에서 기원후 9999년 12월 31일 사이의 날짜 및 시간 값 |
| timestamp | 날짜와 시간(밀리세컨드까지 표시) |
| long | 가변 길이 문자 데이터(1~2gbyte) |
| clob | 단일 바이트 가변 길이 문자 데이터(1~4gbyte) (요즘은 long보다 clob을 더 많이 사용) |
| raw(n) | n byte의 원시 이진 데이터(1~2000byte), 바이너리 데이터 저장 |
| long raw | 가변 길이 원시 이진 데이터(1~2gbyte) |
| blob | 가변 길이 이진 데이터(1~4gbyte), 바이너리 데이터 저장 |
| bfile | 가변 길이 외부 파일에 저장된 이진 데이터(1~4gbyte) |
*테이블 생성
CREATE TABLE employee(
empno NUMBER(6),
name VARCHAR2(30) NOT NULL, --30바이트(글자수 아님)
--오라클xe에서는 한글을 3바이트로 처리해서 한글 10자 저장 가능
salary NUMBER(8,2),
hire_date DATE DEFAULT SYSDATE,
CONSTRAINT employee_pk PRIMARY KEY(empno) --employee_pk: 오라클에서 사용하는 식별자
);
*데이터 추가 및 커밋
INSERT INTO employee (empno,name,salary)
VALUES (100, '홍길동', 1000.23);
COMMIT;
*테이블 생성시 PRIMARY KEY 및 FOREIGN KEY 제약 조건 추가하기
--부모테이블 생성
CREATE TABLE suser (
id VARCHAR2(20),
name VARCHAR2(30),
CONSTRAINT suser_pk PRIMARY KEY (id)
);
--자식테이블 생성
CREATE TABLE sboard(
num NUMBER, --길이를 주지 않으면 최대치로 설정됨
id VARCHAR2(20) NOT NULL,
content VARCHAR2(4000) NOT NULL,
CONSTRAINT sboard_pk PRIMARY KEY (num),
CONSTRAINT sboard_fk FOREIGN KEY (id) REFERENCES suser (id) --부모테이블(suser)로부터 id 참조
);
-무결성 제약조건 위배
INSERT INTO sboard(num, id, content) VALUES (3, 'blue', '모레는 일요일'); --무결성 제약조건 위배
DELETE FROM suser WHERE id='sky'; --무결성 제약조건 위배
*테이블의 관리(DDL문)
-ADD 연산자: 테이블에 새로운 컬럼을 추가
ALTER TABLE employee ADD (addr VARCHAR(2));
-ADD CONSTRAINT: 제약조건 추가
ALTER TABLE employee ADD CONSTRAINT employee_pk PRIMARY KEY (empno);-테이블은 하나의 기본키만 가질 수 있기 때문에 이미 기본키가 있는 상태에서는 에러가 뜸
-MODIFY 연산자: 테이블의 컬럼을 수정하거나 NOT NULL 컬럼으로 변경할 수 있음
ALTER TABLE employee MODIFY salary NUMBER(10, 2) NOT NULL;
-RENAME ~ TO
-컬럼명 변경
ALTER TABLE employee RENAME COLUMN salary TO sal;
-테이블명 변경
RENAME employee TO employee2;
*DROP: 테이블의 삭제
DROP TABLE employee2;-테이블을 삭제하면 복원할 수 없음.
-COMMIT, ROLLBACK은 DML문에만 해당.
*기본키/외래키 제약조건 생성 축약형
-식별자는 자동 부여됨
CREATE TABLE s_member(
id VARCHAR2(20) PRIMARY KEY, --기본키 제약조건
name VARCHAR2(30)
);
CREATE TABLE s_member_detail(
num NUMBER PRIMARY KEY,
content VARCHAR2(4000) NOT NULL,
id VARCHAR2(20) NOT NULL REFERENCES s_member (id) ON DELETE CASCADE --외래키 제약조건
);-ON DELETE CASCADE
-외래키 제약조건이 있을 때, 부모 테이블의 컬럼을 삭제하면 자식 테이블의 자식 데이터를 모두 삭제되는 옵션
*뷰(VIEW)
논리적으로 하나 이상의 테이블에 있는 데이터의 부분 집합
-데이터 엑세스를 제한하기 위해
-복잡한 질의를 쉽게 작성하기 위해
-데이터 독립성을 제공하기 위해
-동일한 데이터로부터 다양한 결과를 얻기 위해
*VIEW 생성
CREATE OR REPLACE VIEW emp10_view
AS SELECT empno id_number, ename name, sal*12 ann_salary
FROM emp WHERE deptno=10;
-뷰는 가상으로 만들어진 컬럼(Virtual Column)을 제외하면 원칙적으로는 수정이 가능하고 삭제도 가능
-삽입은 여러 제약 조건과 virtual column 사용으로 제약이 많음
-뷰를 수정하거나 삭제하면 원본데이터에 영향을 줌
-따라서 뷰는 읽기 전용으로만 사용하는 것이 바람직함
*View를 통한 데이터 변경하기
-일반적으로 view는 조회용으로 많이 사용되지만 아래와 같이 데이터를 변경할 수 있음
-프라이머리키나 Virtual Column은 변경 불가
-뷰의 데이터를 수정하면 원본도 수정됨
UPDATE emp10_view SET name='SCOTT' WHERE id_number=7839;
*View에 데이터 삽입하기
-가상 열 때문에 등록 제한, 가상 열을 제외하면 삽입 가능
INSERT INTO emp10_view(id_number, name, ann_salary) VALUES(8000, 'JOHN', 19000);
-WITH READ ONLY: 읽기 전용 뷰 생성 옵션
CREATE OR REPLACE VIEW emp20_view
AS SELECT empno id_number, ename name, sal*12 ann_salary
FROM emp WHERE deptno=20
WITH READ ONLY;
*View의 수정
-생성과 동일 키워드: CREATE OR REPLACE
CREATE OR REPLACE VIEW emp10_view (id_number, name, sal, department_id)
AS SELECT empno, ename, sal, deptno
FROM emp
WHERE deptno=10;
*시퀀스(Sequence)
-유일한 값을 생성해주는 오라클 객체
-시퀀스를 생성하면 기본키와 같이 순차적으로 증가하는 컬럼을 자동적으로 생성할 수 있음
-보통 primary key 값을 생성하기 위해 사용
| create sequence sequence_name start with n increment by n maxvalue n | nomaxvalue minvalue n | nominvalue cycle | nocycle start with : 시퀀스의 시작 값을 지정. n을 1로 지정하면 1부터 순차적으로 시퀀스번호가 증가 increment by : 시퀀스의 증가 값을 말함. n을 2로 하면 2씩 증가 start with를 1로 하고 increment by를 2로 하면 1,3,5,7.... 이런식으로 시퀀스 번호 증가 maxvalue n | nomaxvalue : maxvalue는 시퀀스가 증가할 수 있는 최대값 nomaxvalue는 시퀀스의 값을 무한대로 지정 minvalue n | nominvalue : minvalue는 시퀀스의 최소값을 지정 기본값은 1이며, nominvalue를 지정할 경우 최소값은 무한대 |
*시퀀스 생성
-시작 값이 1이고 1씩 증가하고 최대값이 100000이 되는 시퀀스 생성
CREATE SEQUENCE test_seq
START WITH 1
INCREMENT BY 1
MAXVALUE 100000;
*시퀀스 관련 명령어
-CURRVAL: 현재 값을 반환
-NEXTVAL: 현재 시퀀스 값의 다음 값 반환
SELECT test_seq.CURRVAL FROM dual;
SELECT test_seq.NEXTVAL FROM dual;
*시퀀스 수정
-START WITH는 수정할 수 없음
ALTER SEQUENCE test_seq
INCREMENT BY 5;
*시퀀스 삭제
DROP SEQUENCE test_seq;
[SUBQUERY 연습문제]
8.총급여(sal+comm)가 평균 급여보다 많은 급여를 받는 사람의 부서번호, 이름, 총급여, 커미션을 출력하시오.
(커미션은 유(O), 무(X)로 표시하고 컬럼명은 "comm유무"로 출력)
[MY ANSWER] --오답
SELECT e.ename, e.sal, d.loc
FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(sal)
FROM emp
WHERE d.loc='CHICAGO');
[IN CLASS1] --조인 방식
SELECT e.ename, e.sal, d.loc
FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(e.sal)
FROM emp e, dept d
WHERE e.deptno=d.deptno AND d.loc='CHICAGO');
[IN CLASS2] --서브쿼리 방식
SELECT e.ename, e.sal, d.loc FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(sal)
FROM emp
WHERE deptno IN(SELECT deptno
FROM dept
WHERE loc='CHICAGO'));
--CHICAGO는 유니크한 값이 아니기 때문에 IN 연산자 사용
9.CHICAGO 지역에서 근무하는 사원의 평균 급여보다 높은 급여를 받는 사원의 이름과 급여, 지역명을 출력하시오.
[MY ANSWER] --오답
SELECT e.ename, e.sal, d.loc FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(sal) FROM emp WHERE d.loc='CHICAGO');
[IN CLASS1] --조인 방식
SELECT e.ename, e.sal, d.loc FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(e.sal) FROM emp e, dept d WHERE e.deptno=d.deptno AND d.loc='CHICAGO');
[IN CLASS2] --서브쿼리 방식
SELECT e.ename, e.sal, d.loc FROM emp e, dept d WHERE e.deptno=d.deptno
AND e.sal > (SELECT AVG(sal) FROM emp WHERE deptno IN(SELECT deptno FROM dept WHERE loc='CHICAGO'));
--CHICAGO는 유니크한 값이 아니기 때문에 IN 연산자 사용-조인방식에서는 서브쿼리 내에서 다시 조인을 해야함. 단순한 서브쿼리에서는 내부쿼리가 외부쿼리에 독립적으로 실행될 수 있어야 함.
10.커미션이 없는 사원들 중 월급이 가장 높은 사원의 이름과 급여등급을 출력하시오.
[MY ANSWER] --쓸데없이 돌아감
SELECT e.ename, s.grade FROM emp e, salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal
AND e.empno = (SELECT empno FROM emp WHERE sal = (SELECT MAX(sal) FROM emp WHERE comm IS NULL));
[IN CLASS]
SELECT e.ename, s.grade
FROM emp e, salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal
AND e.sal = (SELECT MAX(sal)
FROM emp
WHERE comm IS NULL);
11.SMITH의 직속상사(mgr)의 이름과 부서명, 근무지역을 출력하시오.
[MY ANSWER] --오답
SELECT e.ename, d.dname, d.loc FROM emp e, dept d, emp m
WHERE e.deptno=d.deptno
AND e.mgr = m.empno
AND e.empno = (SELECT mgr FROM emp WHERE ename='SMITH');
[IN CLASS]
SELECT e.ename, d.dname, d.loc
FROM emp e JOIN dept d
USING(deptno)
WHERE e.empno IN(SELECT mgr FROM emp WHERE ename='SMITH');
--SMITH는 프라이머리키가 아니기 때문에 IN 연산자 사용
12.ALLEN보다 급여를 많이 받는 사람 중에서 입사일이 가장 빠른 사원과 동일한 날짜에 입사한 사원의 이름과 입사일, 급여를 출력하시오.
[MY ANSWER] --쓸데없이 돌아감
SELECT ename, hiredate, sal FROM emp
WHERE hiredate = (SELECT MIN(hiredate)
FROM (SELECT ename, hiredate, sal
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE ename='ALLEN')));
[IN CLASS]
SELECT ename, hiredate, sal
FROM emp WHERE hiredate = (SELECT MIN(hiredate)
FROM emp
WHERE sal > ALL(SELECT sal
FROM emp
WHERE ename='ALLEN'));
--ALLEN은 프라이머리키가 아니기 때문에 다중행을 사용해야함
--모든 ALLEN의 급여보다 높아야하기 때문에 ALL 연산자 사용'Web Development > SIST' 카테고리의 다른 글
| [Java|HTML|CSS] 6주차 수업: 2024.03.25 - 2024.03.29 (0) | 2024.03.25 |
|---|---|
| [Oracle|PL/SQL|Java] 5주차 수업: 2024.03.18 - 2024.03.22 (0) | 2024.03.22 |
| [Java] 3주차 수업: 2024.03.04 - 2024.03.08 (0) | 2024.03.10 |
| [Java] 2주차 수업: 2024.02.26 - 2024.02.29 (0) | 2024.03.04 |
| [Java] 1주차 수업: 2024.02.16 - 2024.02.23 (1) | 2024.02.26 |


